Overview
This dataset is a set of 164 recordings of untethered ants grasping objects. Each recording is:
- 100FPS
- Covered by 5 camera views - See Setup
- Synchronised acquisition
- Accompanied by written descriptions of behaviour captured on video
- Tagged according to object interaction category
The dataset was developed for use with 3D tracking of animal and object pose throughout the interaction and therefore a subset of the dataset is paired with:
- Calibration videos with provided camera intrinsics and extrinsics
- 2D Ant pose tracking using SLEAP -> Pose Tracking
- 3D Pose reconstruction using mokap -> 3D Pose
- 2D Object pixel occupancy mask -> Object Mask
- 3D Object pose estimation (WIP) -> Object Pose
Setup
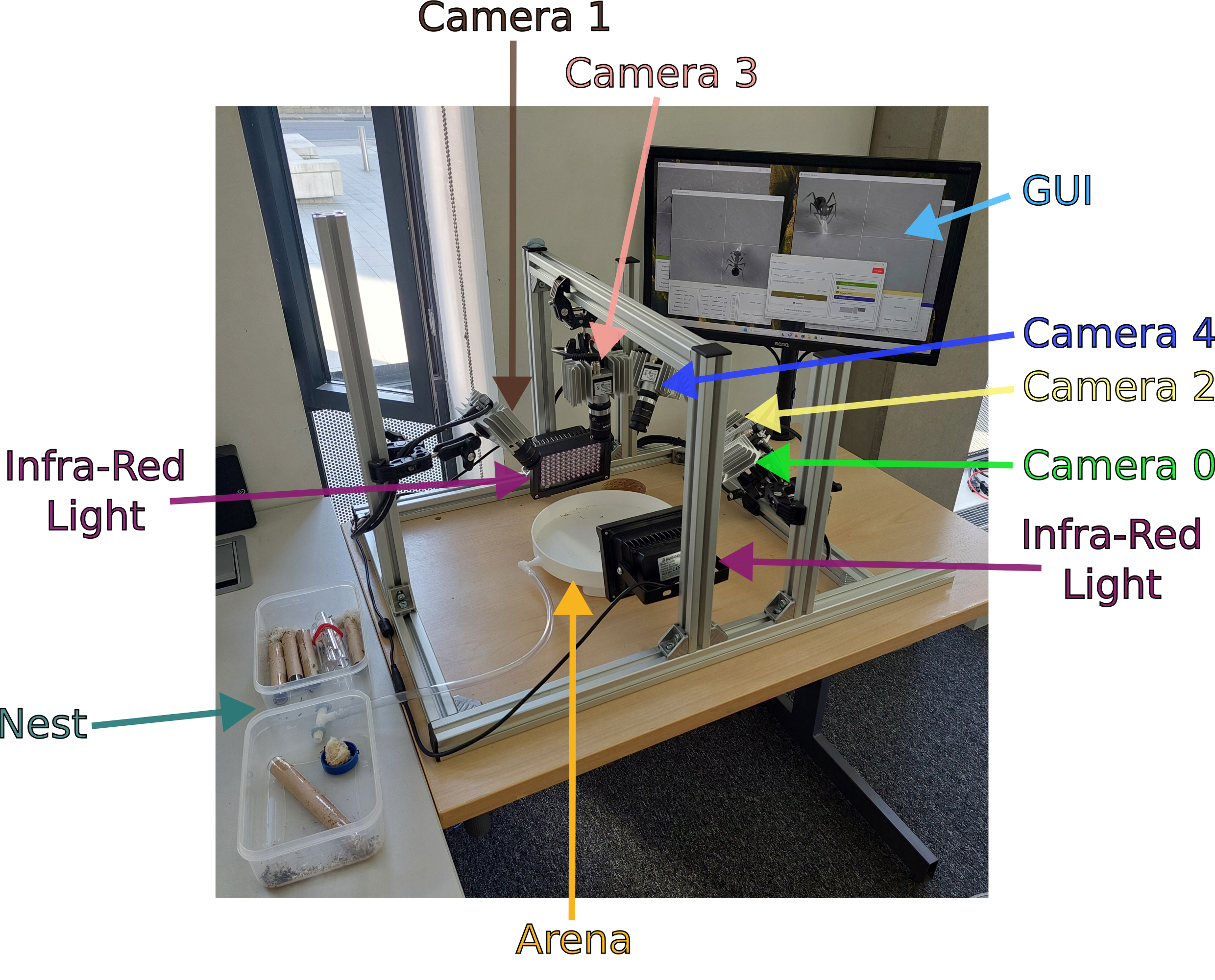 Labelled diagram of the camera arrangement used to collect the video data used in this dataset.
Labelled diagram of the camera arrangement used to collect the video data used in this dataset.
Objects

A series of images containing the different objects used in the experiment sessions.
In the centre of the frame is an image of a ChAruCo marker that was used in the calibration videos. All images are taken from the same camera so the ChAruCo board can be used for scale.
Download
 |
 |
If you would like to download the full dataset or any part of it, follow the instructions here or here.
Example
We’ve included an Example of how this video dataset is being used with the catar repo for 3D pose extraction.
Dataset
Aside from the large quantity of synchronised videos and verbal descriptions, there are additional features in this dataset. The dataset readme.txt contains some additional information on the file structure.
Annotations
For the 3D Pose and Object Mask, the videos were manually annotated. In addition to this, there are verbal descriptions and action tags for each experiment session.
Descriptive
The videos are separated into 4 categories based on the observed behaviour of interest. In the context of recording, we were most interested in how the ants approached and sensed an object before grasping it and the influence of the sensing behaviour on the likelihood of grasp success. Therefore, we organised the videos into the following categories:
- ✅✅ Grasped and carried away
- ✅ Grasped and dropped
- ☑️ Manipulated or pinched but not grasped
- ❌ Sensed but not manipulated
One of the categories in the dataset_description.csv is “Reviewed for Upload?”. In experiments where this says “Yes”, the description and tag have been reviewed since July 2025, the others were last reviewed around December 2024. This time gap allowed for more deliberation on which videos fit in which categories and the specific interesting behaviours to be described. Therefore, experiments that have not been reviewed for upload may have less specific descriptions and incorrect behaviour tags.
| 2D Pose | Object Mask |
|---|---|
 |
 |
2D Animal Pose
Skeleton Keypoints
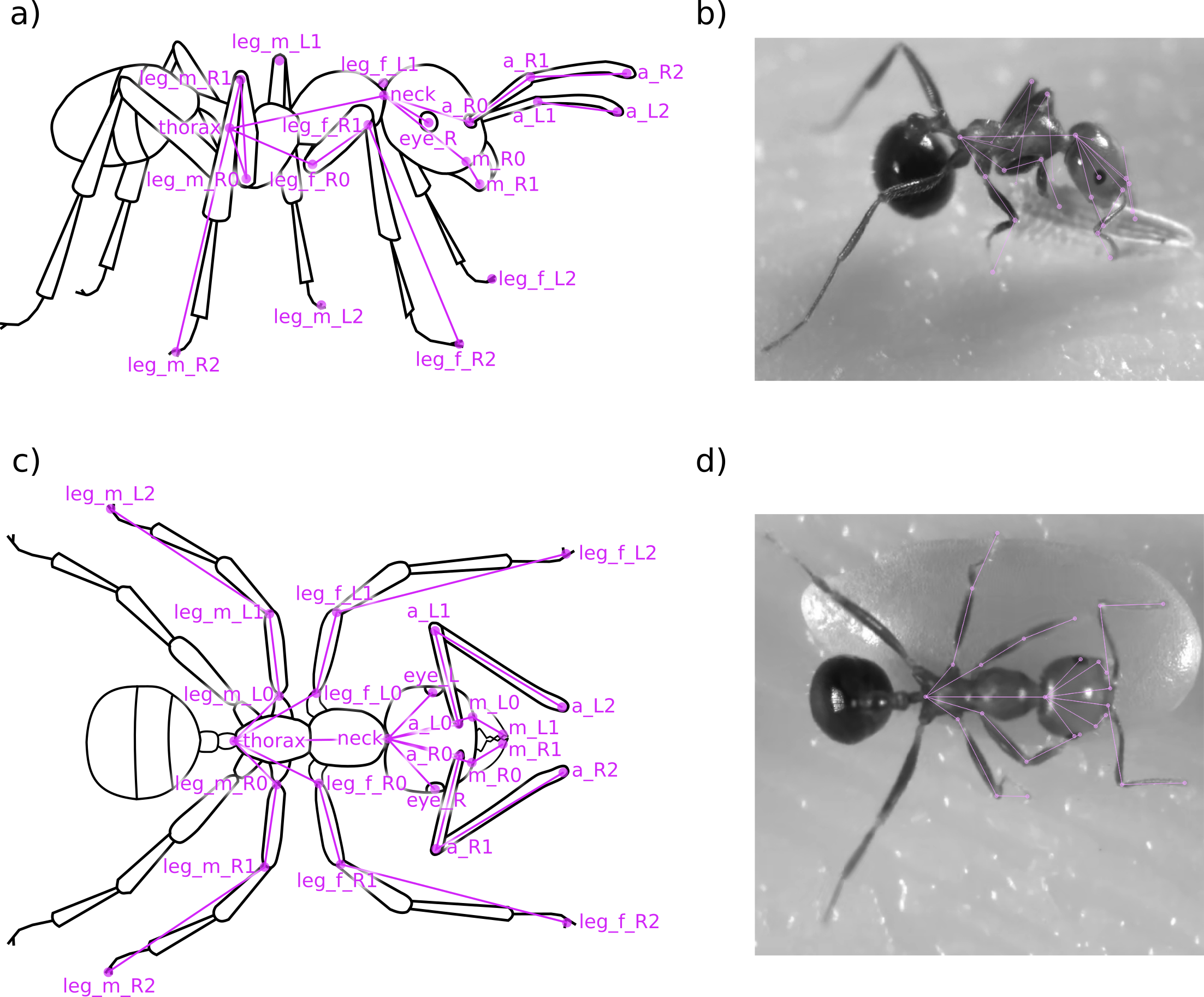
Using sleap.ai, around 500 frames of video were manually annotated for the keypoints shown in the skeleton keypoints.
The annotations are provided in the Annotations/sleap directory, in the form of an .slp project file.
This folder also contains a trained model using a top-down approach.
Object Mask
To extract a pixel occupancy mask, the process was accelerated by using facebookresearch/sam2 to segment the objects.
The pixel annotations used to train the SAM2 model are available in the Annotations/object_mask/input directory as .csv.
The code used to train the model on University of Edinburgh cluster computing is also available at prolley-parnell/SAM2_cluster.
3D Animal Pose
Using the mokap repository, the 2D keypoints can be combined into 3D keypoint poses for the frames in the videos where calibration parameters are good.
The output of this process can be found in Data/240905-1616/outputs/tracking directory as tracklets_*.pkl files.
To read these files, use the repo prolley-parnell/3d_ant_analysis.
Some further research has been carried out on how to extract a reliable 3D pose from multiple viewpoints in Example.
Object Pose
To generate the 3D object pose, the 2D pixel occupancy masks were combined using the camera parameters and voxel carving then using Iterative Closest Pairs (ICP) to match between the poses of sequential meshes. The code to achieve this is also in mokap.
The output of this pose tracking is Data/240905-1616/outputs/segmentation.
This folder contains both the .toml file with pose transforms from the reference frame, as well as the .dae of the reference frame.
Due to the object being tracked having rotational symmetry and being partially occluded by ants, the pose tracking is unreliable in places.
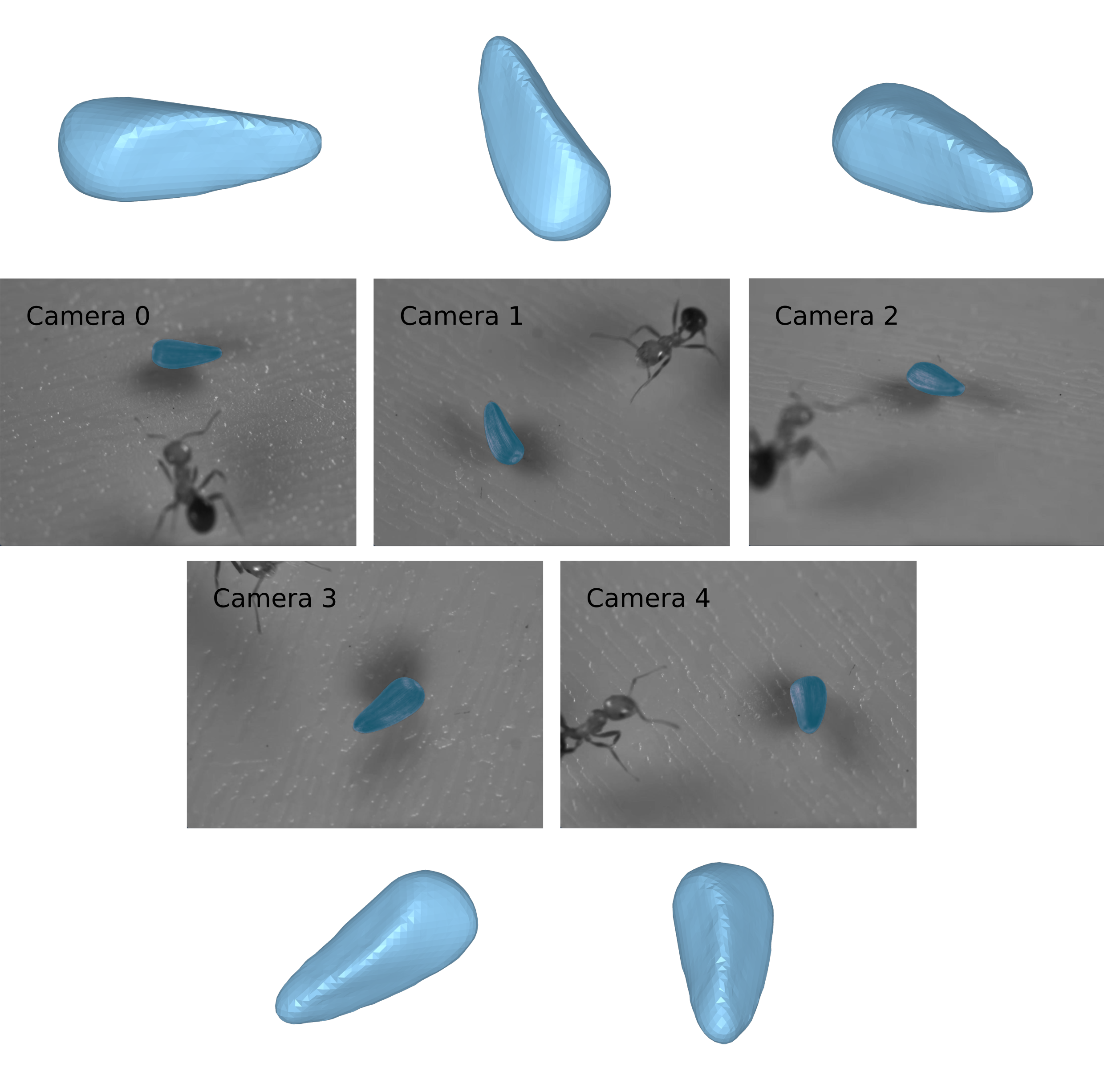
An array of photographs showing the same ant viewed from five different cameras. Each image is annotated with the name of the camera taking the photo, and the object pixel mask is shown in blue. Next to each photograph, the 3D volume created from the pixel mask is shown from the same perspective as the camera.